
Language Models are Open Knowledge Graphs (Paper Explained) YouTube
Building a Knowledge Graph Using Large Language Models. Data Preparation: Begin by collecting and preparing your text data. This might involve cleaning the data, removing unnecessary parts, or.
How to Build a Knowledge Graph in Four Steps The Roadmap From Metadata
As the field of AI advances, models are likely only getting larger, making it increasingly cumbersome to always fine-tuning the entire model end-to-end for every single bespoke task. One form of end-to-end fine-tuning that is often desired, though, is instruction fine-tuning [1]. Large language models are often training on general text.
Operationalizing Enterprise Knowledge Graphs
Speaker: Enrique AlfonsecaLarge Language Models (LLMs) have led to large improvements in state-of-the-art results across language and image understanding and.
Reasoning with Language Models and Knowledge Graphs for Question
The advent of large language models (LLMs) , trained on vast amounts of text data, has been one of the most significant breakthroughs in… · 10 min read · Nov 14, 2023 10

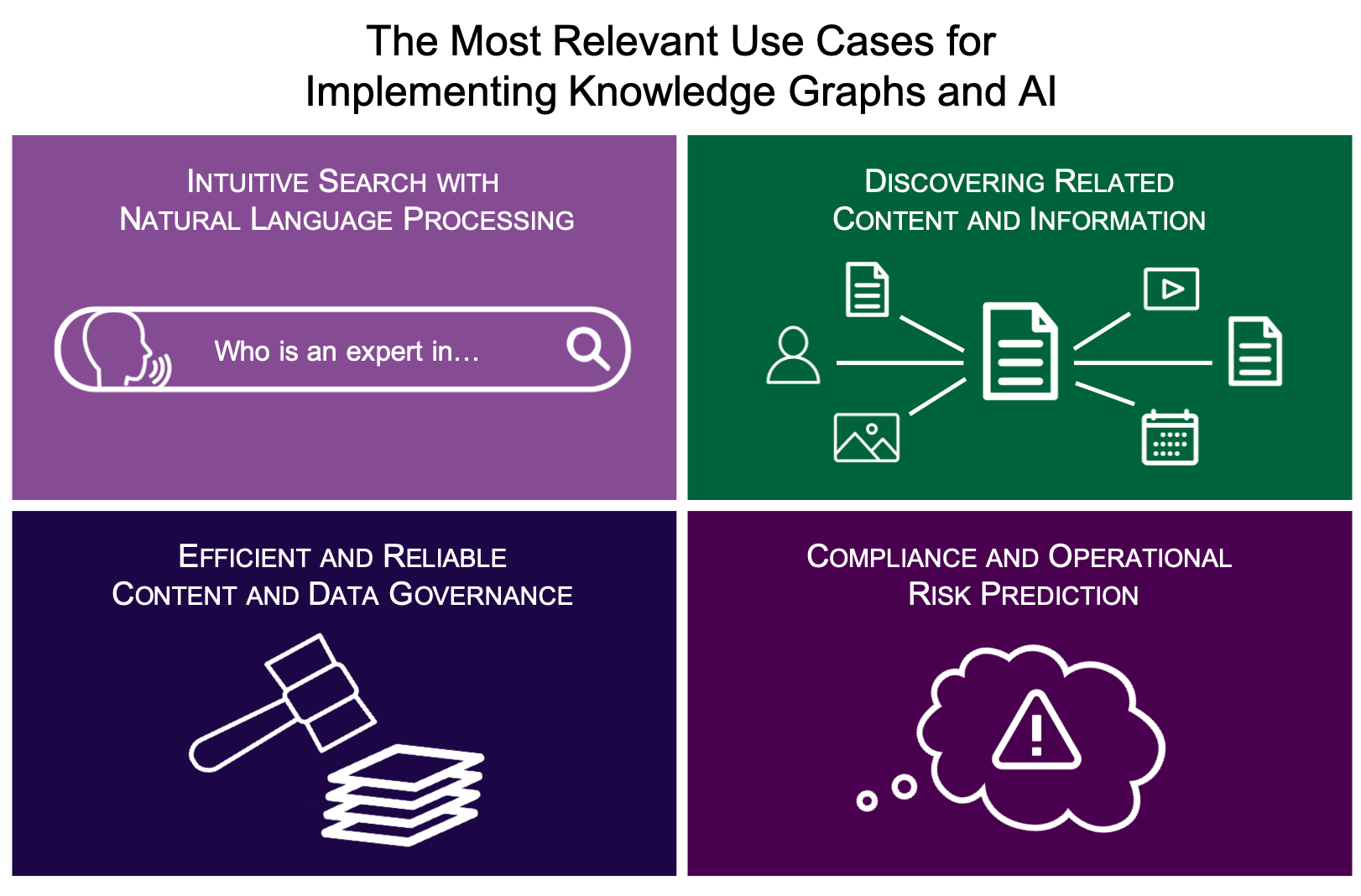
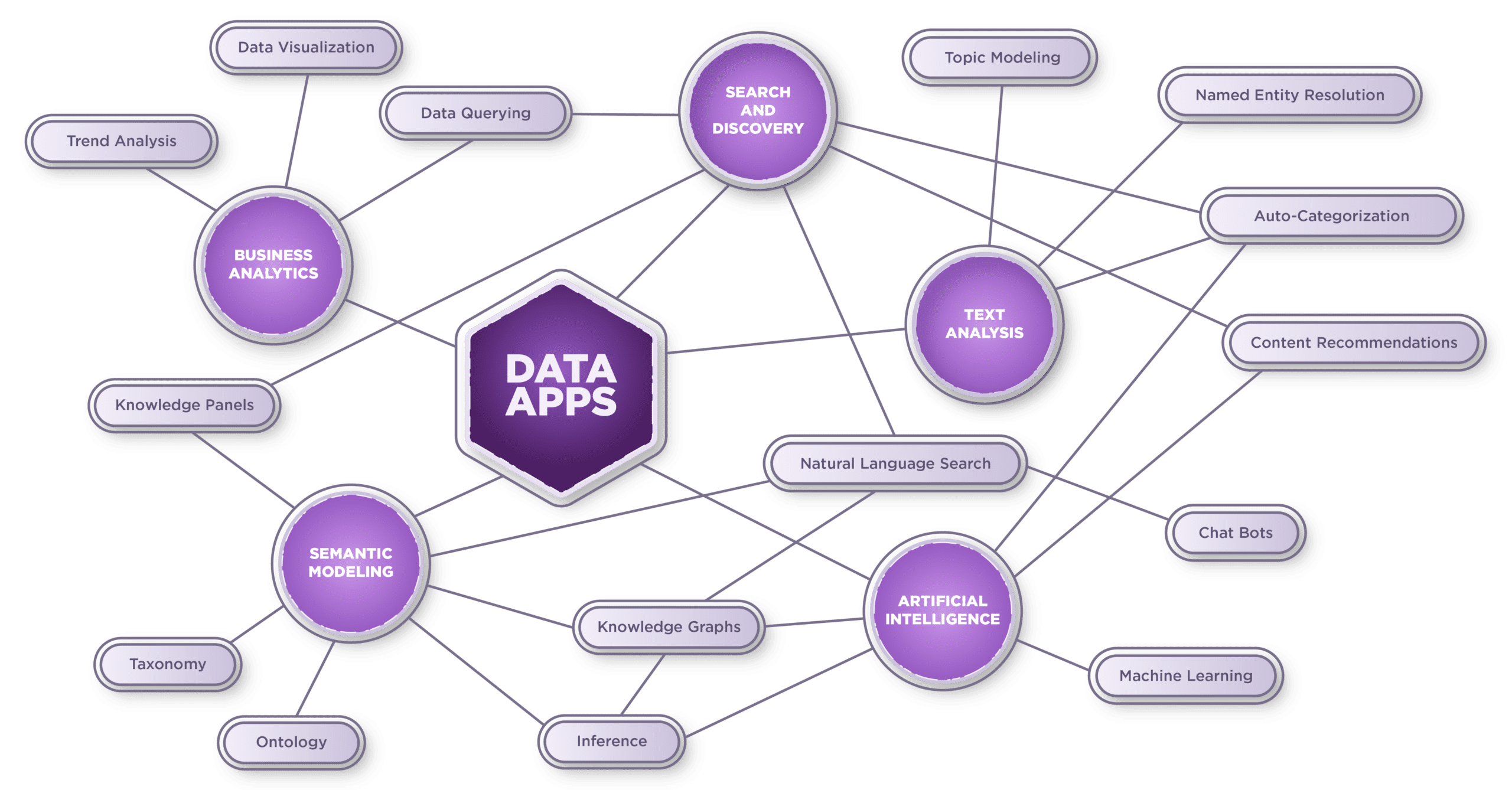
Knowledge Graph Maps 20+ Application and 30+ Capabilities Ontotext
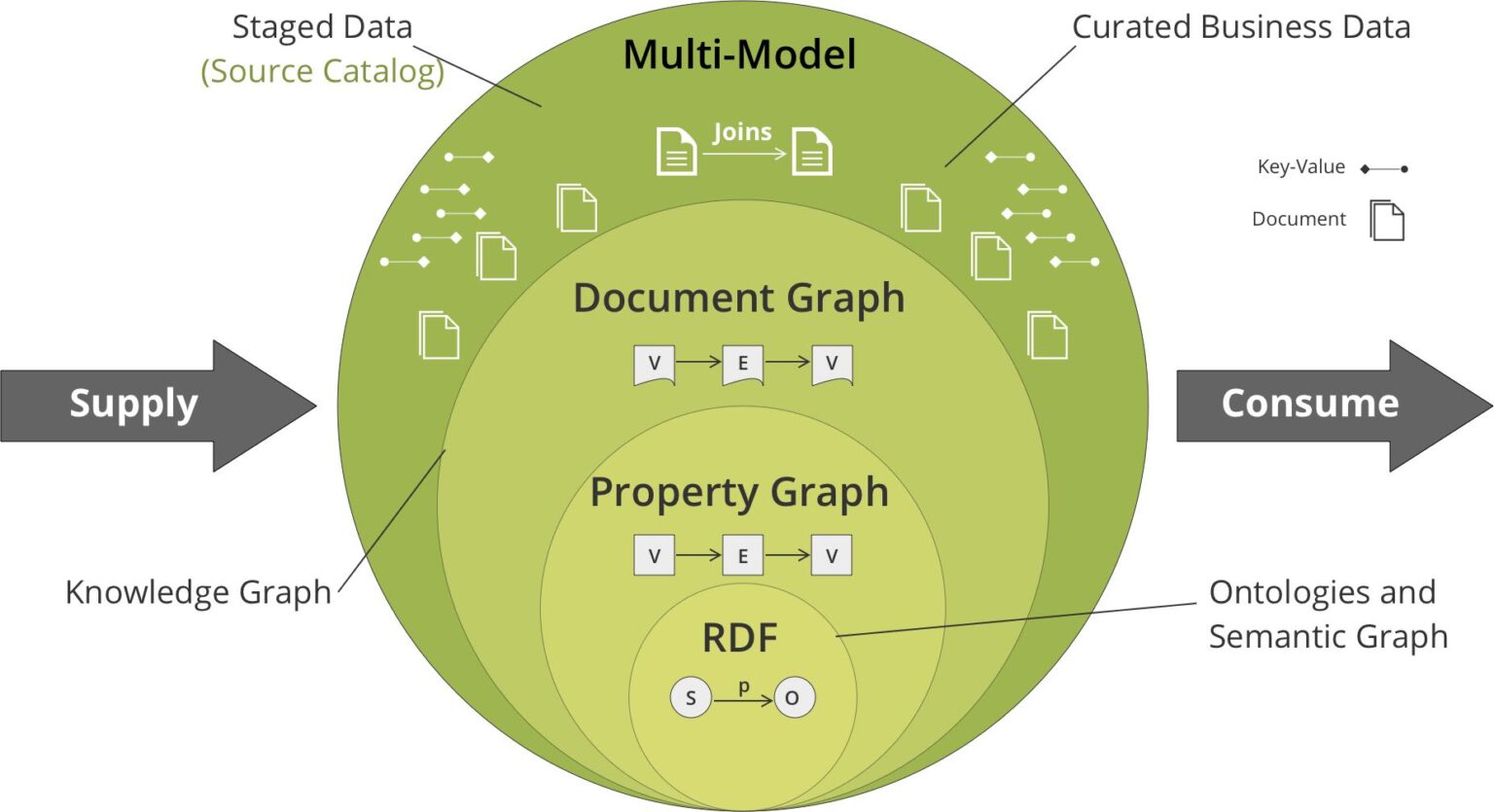
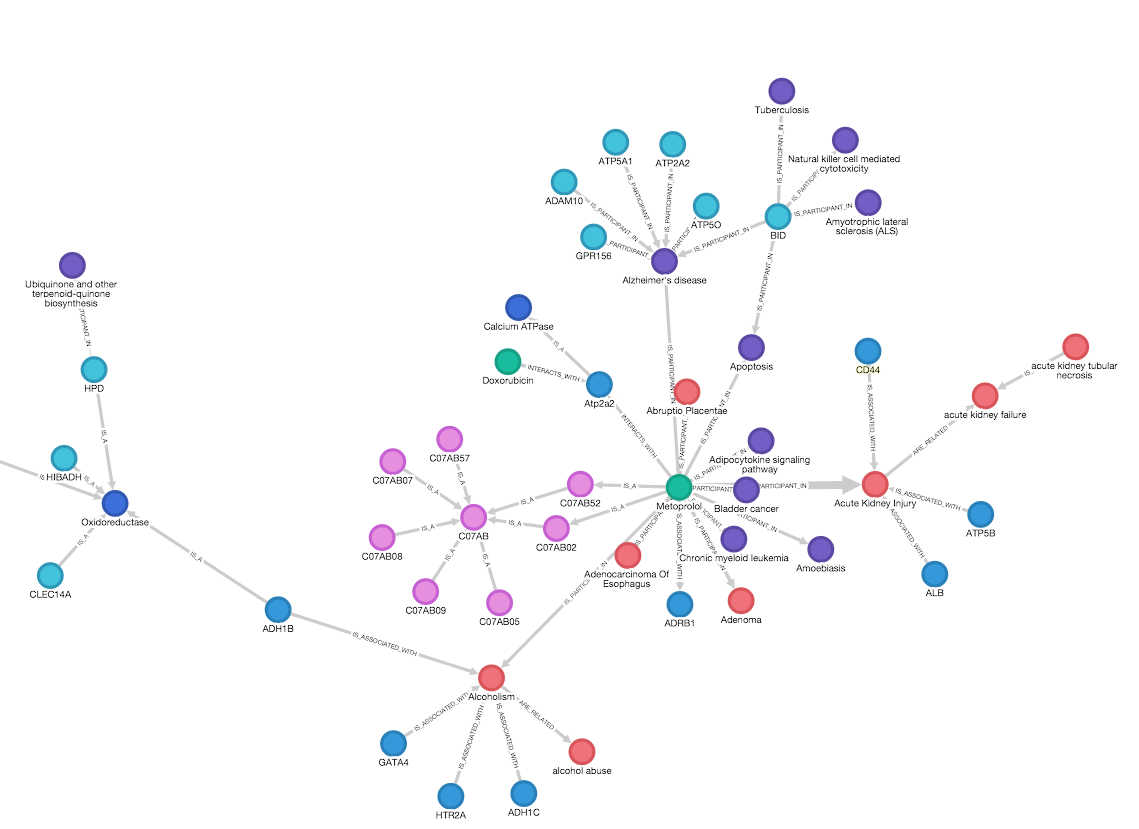
In recent years, knowledge graphs have become an important tool for organizing and accessing large volumes of enterprise data in diverse industries — from healthcare to industrial, to banking and insurance, to retail and more. A knowledge graph is a graph-based database that represents knowledge in a structured and semantically rich format. This could be
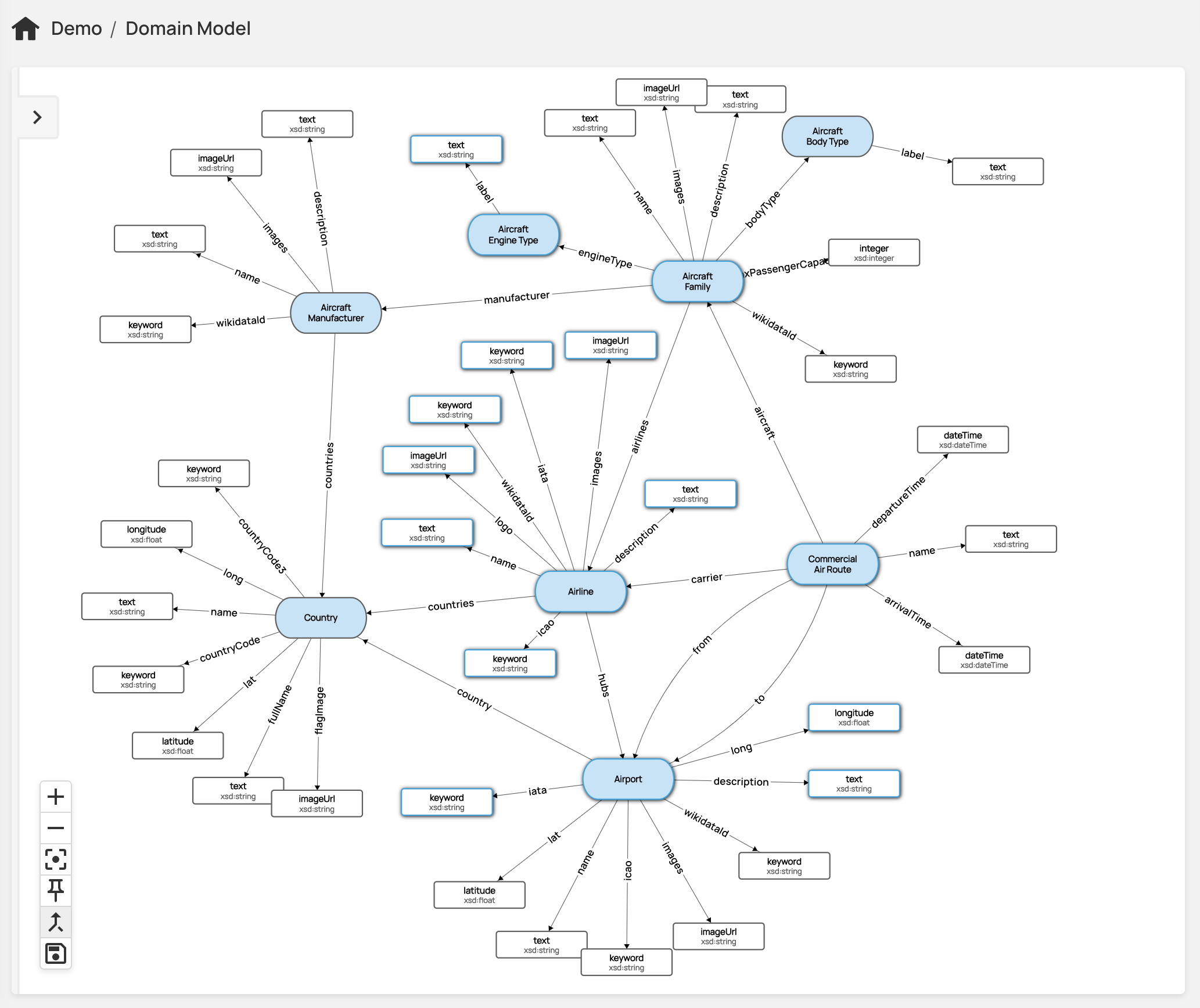
Knowledge Graph Visualization in Data Graphs
In this tutorial, I will demonstrate how to use LangChain agents to create a custom Math application utilising OpenAI's GPT3.5 model. For the application frontend, I will be using Chainlit, an easy-to-use open-source Python framework.This generative math application, let's call it "Math Wiz", is designed to help users with their math or reasoning/logic questions.
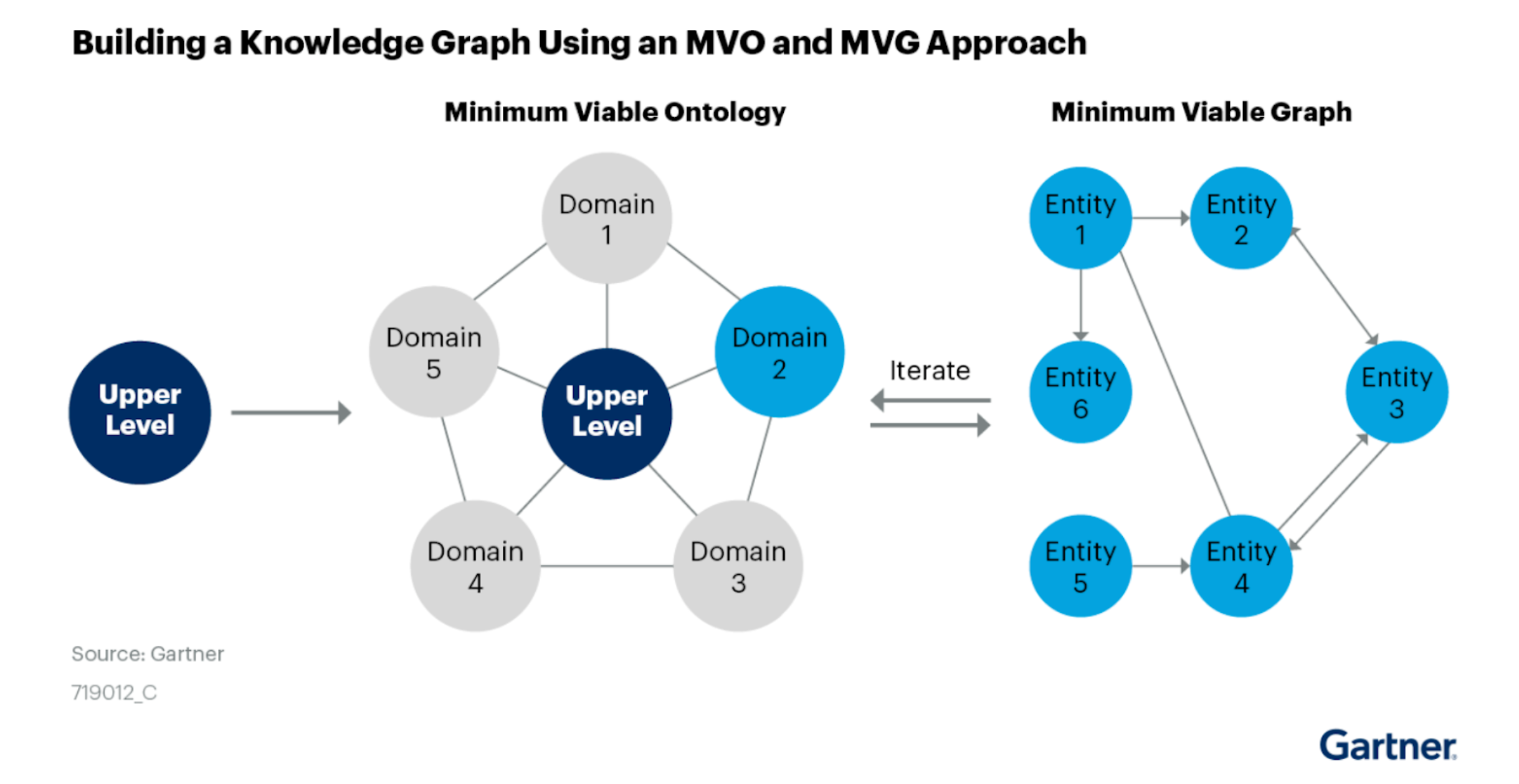
How to Build Knowledge Graphs That Enable AIDriven Enterprise
Knowledge graphs play a vital role in numer-ous artificial intelligence tasks, yet they fre-quently face the issue of incompleteness. In this study, we explore utilizing Large Language Models (LLM) for knowledge graph comple-tion. We consider triples in knowledge graphs as text sequences and introduce an innovative
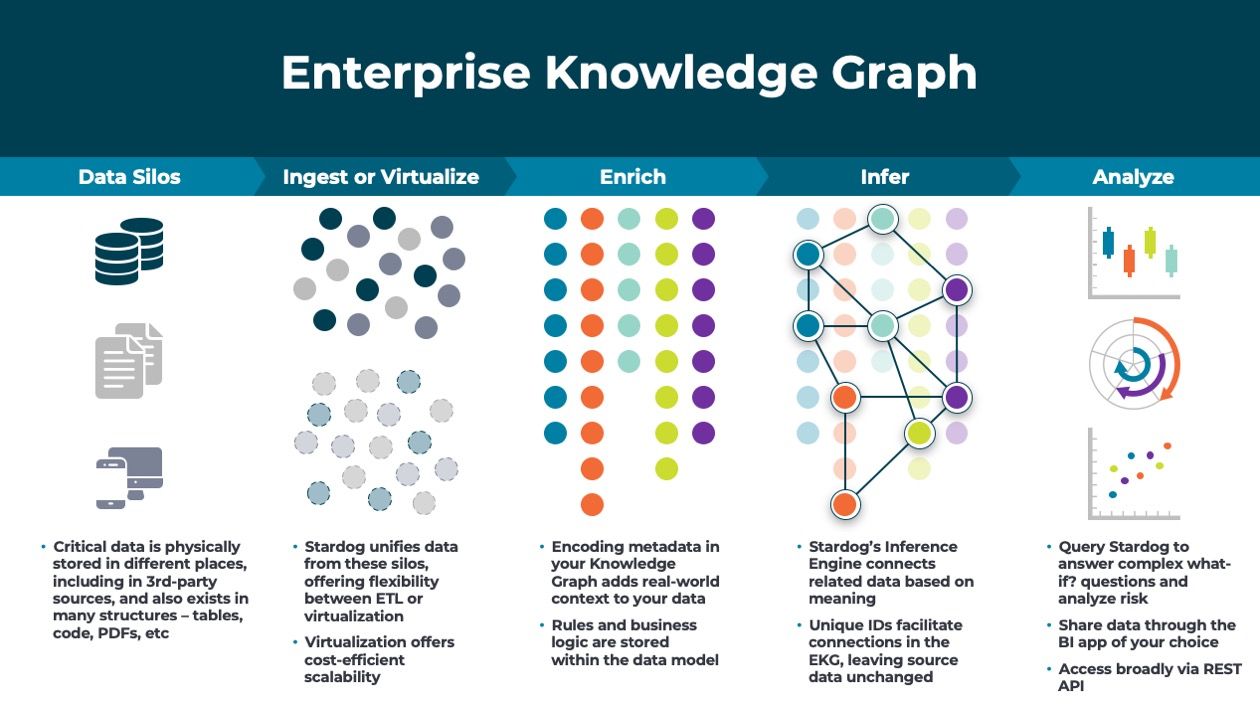
Create your Digital Twin with an Enterprise Knowledge Graph Stardog
Integrating Knowledge Graphs with Large Language Models for More Human-like AI Reasoning Reasoning — the ability to think logically and make inferences from knowledge — is integral to human.

Who's Who in Large Language Model Science? Mapping Science as a Graph
In " Knowledge Graph Based Synthetic Corpus Generation for Knowledge-Enhanced Language Model Pre-training " (KELM), accepted at NAACL 2021, we explore converting KGs to synthetic natural language sentences to augment existing pre-training corpora, enabling their integration into the pre-training of language models without architectural changes.
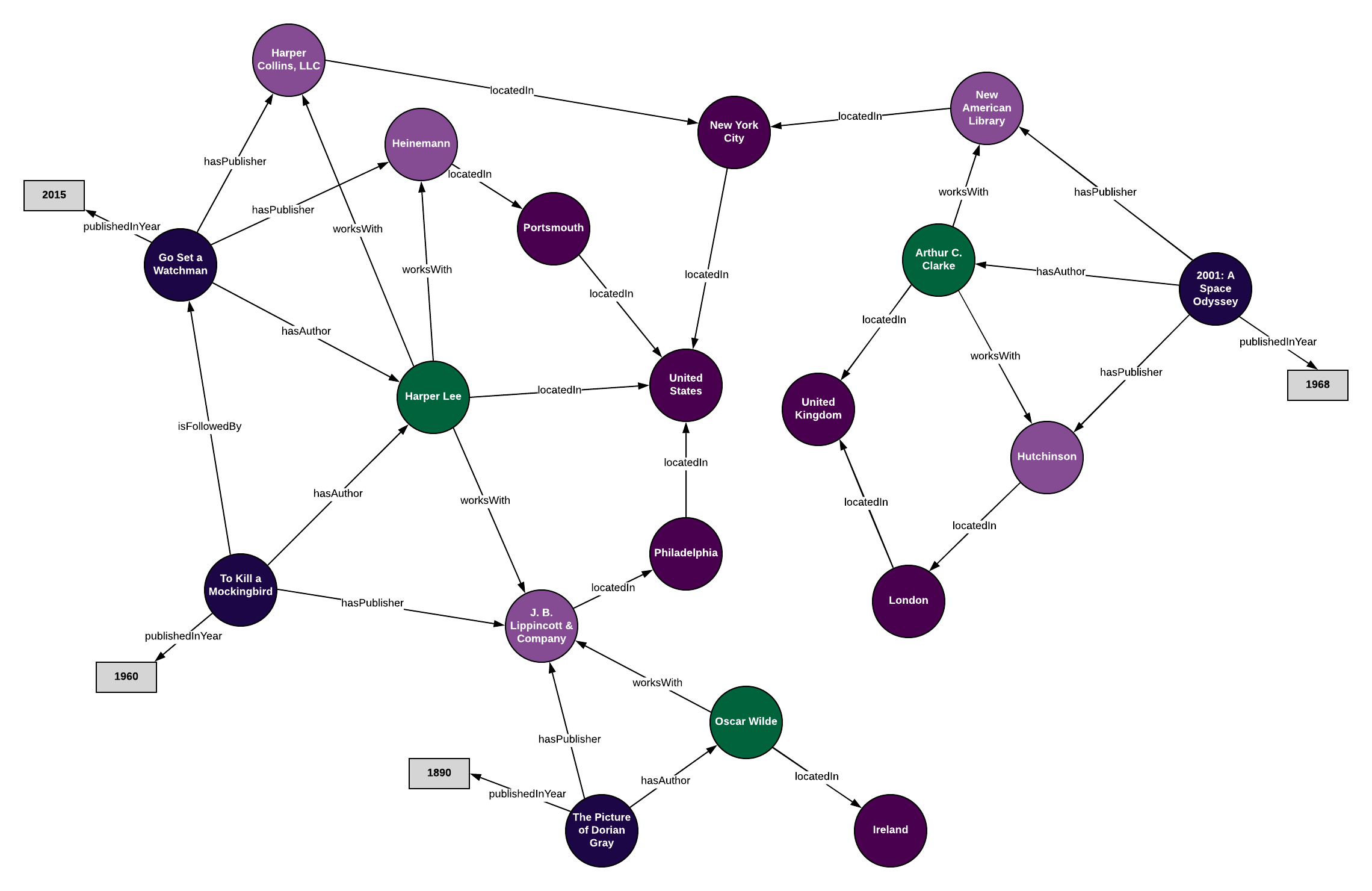
What's the Difference Between an Ontology and a Knowledge Graph
We are excited to reveal that NebulaGraph now supports Text2Cypher, a combined Graph + LLM technology that translates natural language into graph queries. Through a dialogue interface, users can effortlessly construct and query knowledge graphs using natural language. Additionally, we provide a turnkey enterprise-level service.

What is a Knowledge Graph? Ontotext Fundamentals
Linked knowledge graphs build the backbone of many data-driven applications such as search engines, conversational agents and e-commerce solutions. Declarative link discovery frameworks use complex link specifications to express the conditions under which a link between two resources can be deemed to exist. However, understanding such complex.

Graph Databases for Beginners The Basics of Data Modeling
Large language models (LLMs), such as ChatGPT and GPT4, are making new waves in the field of natural language processing and artificial intelligence, due to their emergent ability and generalizability. However, LLMs are black-box models, which often fall short of capturing and accessing factual knowledge. In contrast, Knowledge Graphs (KGs), Wikipedia and Huapu for example, are structured.
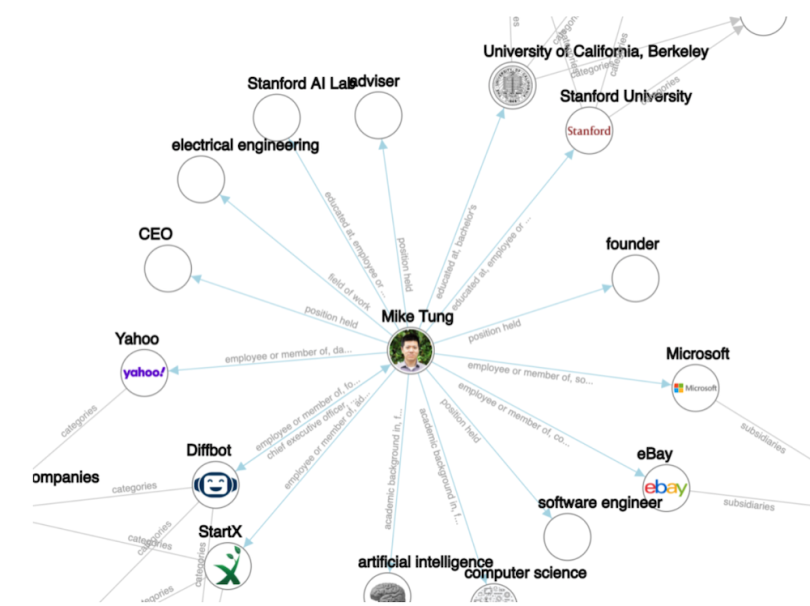
What Is a Knowledge Graph? Examples, Uses & More. Built In
The innovations discussed in this survey demonstrate initial progress in amalgamating the complementary strengths of linguistic knowledge in large language models and structured knowledge in graphical databases. However, notable gaps remain before this integration can extend beyond prototypes to performant systems deployed in the real world.
How Knowledge Graphs Will Transform Data Management And Business The
Step 3: Creating the query to generate data. The third step in generating a knowledge graph involves creating the Cypher query to generate data for the graph database. The query is generated using.
Reasoning with Language Models and Knowledge Graphs for Question
knowledge graphs. Index Terms—ChatGPT, REBEL, LLMs, Relation-extraction, NLP, Sustainability I. INTRODUCTION The technological advancements, together with the avail-ability of Big Data, have led to a surge in the development of Large Language Models (LLMs) [1]. This trend has paved the way for a cascade of new models being released on a regular
Knowledge Graphs & Data Modeling Enterprise Knowledge
The Impact of Large Language Models on Knowledge Management With technological advancements, Large Language Models are revolutionizing business insights, efficiency, and strategic decision-making. This integration enhances enterprise knowledge management, offering actionable strategies, insights, and innovative solutions.
